深度学习推荐系统的工程实现概要 数据处理与存储服务
在深度学习推荐系统的工程实现中,数据处理和存储服务构成了系统的核心基础。这些服务不仅决定了推荐模型的输入质量,还直接影响系统的可扩展性、实时性和稳定性。
数据处理的工程流程
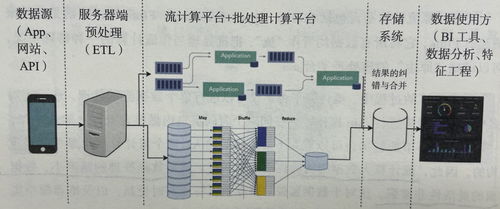
数据处理主要包括数据采集、清洗、特征工程和样本生成等环节。系统通过日志收集用户行为数据(如点击、浏览、购买记录)、物品属性数据以及上下文信息。这些原始数据往往存在噪声和缺失值,需经过清洗和归一化处理。随后,特征工程阶段将原始数据转化为模型可用的特征,包括数值型特征(如用户年龄、物品价格)、类别型特征(如用户性别、物品类别)以及序列特征(如用户历史行为序列)。对于深度学习模型,常采用嵌入技术将高维稀疏特征映射为低维稠密向量。样本生成模块根据正负样本比例构建训练集,并可能引入负采样策略以应对数据不平衡问题。
存储服务的架构设计
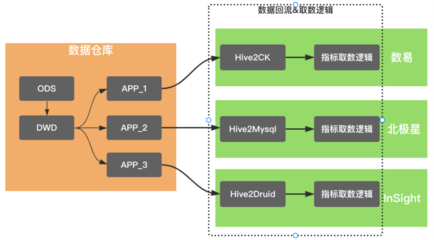
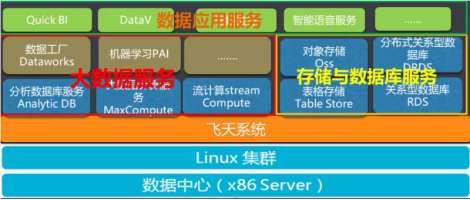
存储服务需支持海量数据的高效存取,通常采用分层存储架构。实时数据(如用户实时行为)存入低延迟的NoSQL数据库(如Redis或HBase),以支持在线推荐服务的即时响应。批处理数据(如历史行为日志)则存储在分布式文件系统(如HDFS)或数据仓库(如Hive)中,用于离线模型训练。特征存储系统(如Feast或Tecton)专门管理特征数据,确保特征的一致性复用和快速检索。元数据存储(如MySQL)用于记录数据版本、模型版本和实验配置,保障系统的可追溯性。
关键挑战与优化策略
工程实践中,数据处理和存储面临数据一致性、实时性与成本控制的挑战。为保障数据一致性,需实施严格的数据血缘追踪和Schema管理。实时性方面,通过流处理框架(如Flink或Kafka Streams)实现实时特征计算,减少数据延迟。成本控制则依赖数据生命周期管理,例如对冷热数据实施分层存储,并采用数据压缩技术减少存储开销。
高效的数据处理和存储服务是深度学习推荐系统成功落地的基石。通过模块化设计、自动化流水线及智能监控,工程团队能够构建出高可靠、低延迟的数据基础设施,从而驱动推荐模型持续优化与业务增长。
如若转载,请注明出处:http://www.lookmq.com/product/19.html
更新时间:2026-04-16 15:40:04