快狗打车实时数仓演进之路 数据处理与存储服务的架构升级
随着快狗打车业务的快速增长,对实时数据的需求日益迫切。数据处理和存储服务作为实时数仓的核心模块,经历了从传统批处理到实时流处理的演进。
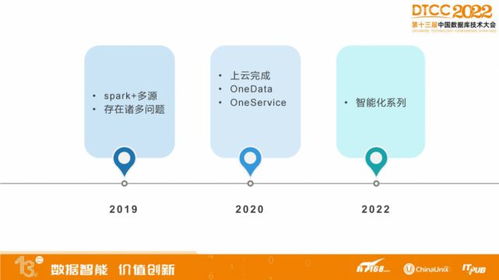
初始阶段,快狗打车采用基于Hadoop的离线数仓架构,数据通过T+1方式批量处理,延迟高且无法满足实时业务场景。随着用户规模扩大,实时调度、定价策略和运营分析对数据时效性要求提升。
快狗打车数据处理服务演进过程主要分为三个关键阶段:
第一阶段,引入Kafka作为数据总线,将业务系统产生的订单、位置和用户行为数据实时采集到消息队列。数据处理层采用Spark Streaming进行初步的ETL操作,实现数据清洗和格式标准化。
第二阶段,构建分层数据处理架构。基于Lambda架构,同时支持批处理和流处理两条数据通道。实时流处理使用Flink替换部分Spark Streaming组件,提供更低的处理延迟和Exactly-Once语义保障,满足订单状态追踪、司机位置更新等核心业务的实时需求。
第三阶段,实现流批一体和智能化处理。借助Flink的流批统一引擎,简化数据处理逻辑;引入机器学习模型,对实时流量进行异常检测和预测分析;建立数据质量监控体系,确保数据处理过程的准确性和完整性。
在数据存储服务方面,演进路径同样清晰:
初期使用HDFS和Hive存储历史数据,MySQL存储维度表。随着实时查询需求增加,引入ClickHouse作为OLAP引擎,支持多维度实时分析。针对不同的数据访问模式,建设了多级存储体系:
- 热数据存储在Redis和Elasticsearch中,支持毫秒级查询响应
- 温数据存储在ClickHouse,支持复杂分析查询
- 冷数据归档至HDFS,满足合规和长期存储需求
通过构建统一数据服务层,对外提供标准化的数据访问接口,屏蔽底层存储差异,降低业务方使用门槛。
当前,快狗打车实时数仓每天处理数十TB数据,支撑着智能调度、动态定价、风险控制等核心业务场景。数据处理延迟从小时级降至秒级,数据存储成本通过分层策略得到有效控制。
快狗打车将持续优化数据处理和存储服务,探索基于云原生的架构升级,加强数据治理和安全管理,为建设更加智能、高效的实时数据平台奠定坚实基础。
如若转载,请注明出处:http://www.lookmq.com/product/25.html
更新时间:2026-04-16 00:02:52