大数据系统数据采集产品的架构分析 聚焦数据处理与存储服务
随着大数据时代的到来,企业对数据采集、处理与存储的需求日益增长。一个高效的大数据系统数据采集产品,其核心架构通常包括采集层、处理层和存储层。本文将重点分析数据处理与存储服务在这一架构中的关键作用和实现方式。
一、数据采集架构概述
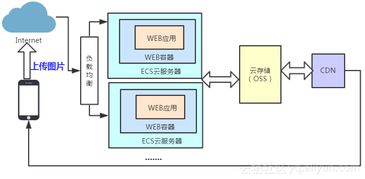
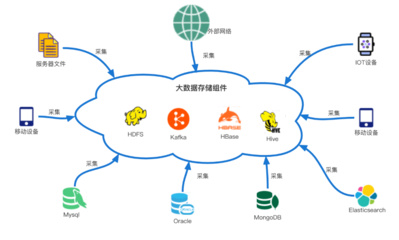
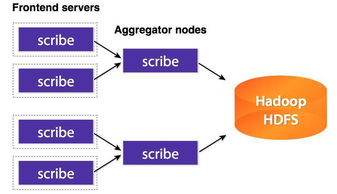
大数据系统数据采集产品通常采用分层架构:采集层负责从多种数据源(如数据库、日志、传感器、API接口等)收集数据;处理层对采集到的数据进行清洗、转换、聚合等操作;存储层则将处理后的数据持久化保存,供后续分析和应用使用。这种架构确保了数据从源头到存储的完整链路,提高了系统的可扩展性和可靠性。
二、数据处理服务的关键模块
数据处理服务是大数据采集产品的核心,主要承担数据质量提升和格式统一的任务。其关键模块包括:
1. 数据清洗模块:去除无效数据、处理缺失值和异常值,确保数据准确性。
2. 数据转换模块:将数据转换为目标格式,如JSON、Avro或Parquet,以适应后续分析需求。
3. 数据聚合模块:对数据进行汇总、分组或计算,生成统计指标或聚合视图。
4. 流处理与批处理模块:支持实时流处理(如Apache Kafka、Flink)和批量处理(如Spark),满足不同场景下的时效性要求。
这些模块通常通过分布式计算框架实现,以提高处理效率和容错能力。
三、数据存储服务的设计要点
数据存储服务负责持久化数据,其架构设计需考虑数据量、访问频率和成本等因素。常见的存储方案包括:
1. 分布式文件系统:如HDFS,适用于存储大规模非结构化数据,支持高吞吐量的读写操作。
2. NoSQL数据库:如HBase、Cassandra,适合存储半结构化或非结构化数据,并提供低延迟的查询能力。
3. 数据湖与数据仓库:数据湖(如AWS S3)存储原始数据,支持灵活的数据探索;数据仓库(如Snowflake、BigQuery)则优化了查询性能,适用于复杂分析。
4. 缓存层:使用Redis或Memcached等工具缓存热点数据,减少对后端存储的压力。
设计时还需关注数据分区、索引策略和数据生命周期管理,以优化存储成本和性能。
四、数据处理与存储的集成实践
在实际应用中,数据处理与存储服务需紧密集成。例如,通过ETL(提取、转换、加载)管道将处理后的数据直接导入存储系统;或采用Lambda架构,结合批处理和流处理,实现数据的高效流动。数据治理工具(如Apache Atlas)可帮助跟踪数据血缘,确保数据从采集到存储的透明性和可追溯性。
五、挑战与未来趋势
尽管大数据采集产品在数据处理和存储方面已取得显著进展,但仍面临数据安全、实时性要求和成本控制等挑战。未来,随着云原生技术和AI驱动的自动化管理的发展,数据处理与存储服务将更加智能化、弹性化,为企业提供更高效的数据支撑。
数据处理和存储服务是大数据系统数据采集产品的关键组成部分,其架构设计直接影响系统的性能和可靠性。通过优化这些服务,企业能够更好地挖掘数据价值,驱动业务创新。
如若转载,请注明出处:http://www.lookmq.com/product/12.html
更新时间:2026-05-30 06:32:57